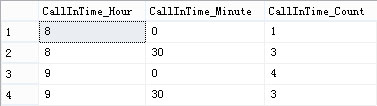
声明:本篇文章的SQL语句为了体现作者的思路,并非最优,请根据实际需要进行优化。
曾经帮别人解决一个这样的问题:
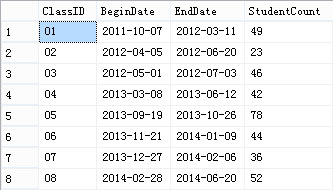
CREATE TABLE [dbo].[E_Classes] ([ClassID] varchar(12) NOT NULL ,[BeginDate] date NULL ,[EndDate] date NULL ,[StudentCount] smallint NULL);
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'01', N'2011-10-07', N'2012-03-11', N'49');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'02', N'2012-04-05', N'2012-06-20', N'23');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'03', N'2012-05-01', N'2012-07-03', N'46');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'04', N'2013-03-08', N'2013-06-12', N'42');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'05', N'2013-09-19', N'2013-10-26', N'78');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'06', N'2013-11-21', N'2014-01-09', N'44');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'07', N'2013-12-27', N'2014-02-06', N'36');
INSERT INTO [dbo].[E_Classes] ([ClassID], [BeginDate], [EndDate], [StudentCount]) VALUES (N'08', N'2014-02-28', N'2014-06-20', N'52');
要求按年和月分别统计全部课程的统计每个月的人天次,即:

计算方法为 (每门课在当月的有效天数*人数)的总和,如2014年01月的应该为 课程06的 2014-01-01~2014-01-09共计9天*44人=396人天 再加上 课程07的2014-01-01~2014-01-31共计31天*36人=1116人天,那么2014年01月的人天为 396+1116=1512人天次。
这个问题看上去挺麻烦的,但是我们可以换个思路去考虑,先建一张序号表:
CREATE TABLE [dbo].[E_Sequence]([Sequence_ID] [int] IDENTITY(1,1) NOT NULL, CONSTRAINT [PK_E_Sequence] PRIMARY KEY CLUSTERED ([Sequence_ID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]);
SET IDENTITY_INSERT [dbo].[E_Sequence] ON
INSERT INTO [dbo].[E_Sequence] (Sequence_ID)
SELECT number FROM [master]..[spt_values] WHERE type = 'P'
UNION ALL
SELECT number + 2048 FROM [master]..[spt_values] WHERE type = 'P'
SET IDENTITY_INSERT [dbo].[E_Sequence] OFF
那。。。这张序号表是干什么用的呢?看看下面就知道了:
SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date FROM E_Sequence
通过这个语句,我们可以生成一个从2011年01月01日开始的4000天,我们将用到这个查询来将课程表的时间段,拆分到每一天去:
SELECT Year(Class_Date) AS Class_Year,
Month(Class_Date) AS Class_Month,
StudentCount
FROM (SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date
FROM E_Sequence) t1,
E_Classes t2
WHERE t1.Class_Date BETWEEN t2.BeginDate AND t2.EndDate
看看效果:
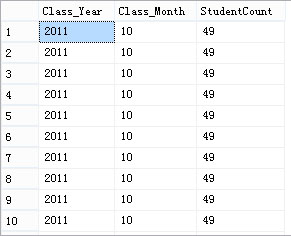
OK,这样,是不是就很明了了呢?“年”字段有了,“月”字段有了,“学生数”是不是就可以简单地加了?然后再一个行列转换就可以实现了(SQL2000请自行转为Case When End):
SELECT Class_Year AS 年分,
Isnull([1], 0) AS 一月,
Isnull([2], 0) AS 二月,
Isnull([3], 0) AS 三月,
Isnull([4], 0) AS 四月,
Isnull([5], 0) AS 五月,
Isnull([6], 0) AS 六月,
Isnull([7], 0) AS 七月,
Isnull([8], 0) AS 八月,
Isnull([9], 0) AS 九月,
Isnull([10], 0) AS 十月,
Isnull([11], 0) AS 十一月,
Isnull([12], 0) AS 十二月
FROM (SELECT Year(Class_Date) AS Class_Year,
Month(Class_Date) AS Class_Month,
studentcount
FROM (SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date
FROM E_Sequence) t1,
e_classes t2
WHERE t1.Class_Date BETWEEN t2.begindate AND t2.enddate) t
PIVOT (Sum(studentcount) FOR Class_Month IN
([1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12])) tpivot
看到了吧?有时,引入一张外表,可以让我们的思路更清楚。
如果将
SELECT Dateadd(day, Sequence_id, '2011-1-1') AS Class_Date FROM E_Sequence
这句生成的查询,直接做成一张日期的序列表再加上索引的话,那在性能上会快更多,具体优化就不多讲了。
继续留个尾巴:
请只统计2012年07月16日到2013年06月15日之间,排除双休日的每个月的人天次。